
Wevoxでエンジニアをしているタガミと申します。Wevoxのフロントエンドエンジニアをやっています。
早速ですが、エンジニアやデザイナーの皆さん。毎日バグ対応と闘っていますか?
日頃プロダクト開発をしていると、バグ対応や軽微なデザインの修正などに関して、ユーザーから直接問い合わせがあったり、あるいは社内の営業メンバーなどを介してだったり、はたまたエンジニアが自ら発見してコミュニケーションをとることもあります。「プロダクトは作ったら終わり!」というプロダクトはいまや少なくなり、新規開発を進めつつ、同時にバグ対応もする、そんなことが当たり前になっているのではないでしょうか。
さらにこうしたバグ対応を複雑化させる要因として、「コミュニケーションツールの多様化」も挙げられると思います。例えば弊社では主にSlackを使っていますが、お客様からはメールや電話で連絡がきます。さらに、zendeskやintercomなどのようにチャットで問い合わせができるツールもあります。一方、エンジニアはbacklogやjiraなどのタスク管理ツール上でコミュニケーションをとっていたりします。こうしたツールの多様化によって、依頼対応のコミュニケーションパスが無数に増えてしまうという風景は珍しくありません。
こうしたコミュニケーションの複雑さはエンジニアやデザイナー側の負担になるだけでなく、依頼する側である営業・CSメンバー、さらにその向こうにいるユーザーの負担にもなり得ます。では、どうすればいいのか?これを整理するためにMVCモデルを利用したいと思います。
結論
以下の三点が大事!
- 属人的、かつ無数に増えるコミュニケーションパスを適度に制限すること(≒Controllerを適切な責務で切り分ける)
- バグ対応の進捗、詳細を適切に共有すること(≒Controllerの処理結果をViewに反映させる)
- バグ修正作業を集約しすぎない、同じような処理をなるべく減らすこと(≒データ処理を行うModel層を責務で切り分ける、また適切なかたちで共通処理を減らす)
MVCとは

MVCはアプリケーションを3つの層、つまりM(Model)・V(View)・C(Controller)に分割するソフトウェアアーキテクチャの名称です。
Viewはアプリケーションにおける見た目を指します。例えば、Wevoxであればサーベイという質問にユーザーが答えますが、その選択肢1つ1つのボタンや、画面のレイアウトなどがViewにあたります。Viewの責務はあくまで見た目に関することのみで、ボタンを押したらデータがどうなるか?については原則関与しません。
続いて、Modelはそのアプリケーションにおけるドメインデータに関わる様々な処理を行います。サーベイへの回答結果をどう処理し、保存するか?などです。原則、Modelは見た目(View)には直接依存しません。例えば「1点」という回答がどういうボタンで、どこに位置しているかなどはもちろん知り得ません。こうすることでView/Modelを疎結合に管理することができます。
そして最後に、これらViewとModelをつなぐControllerが存在します。Controllerはユーザーのアクションに応じて、Modelを呼びます。このアクション内容に複数パターンがあれば、それらをよしななModelに振り分けて呼び出します。そして最終的にその結果をViewに反映することで、ユーザーはそのアクションの結果を目にすることができます。
このMVCアーキテクチャを用いて、バグ対応のフローを整理しておくことで、エンジニア及びビジネスメンバーそれぞれがより効率的にバグ対応を進められ、またプロダクトの改善にもつながります。
1. コミュニケーションパス = エンドポイント
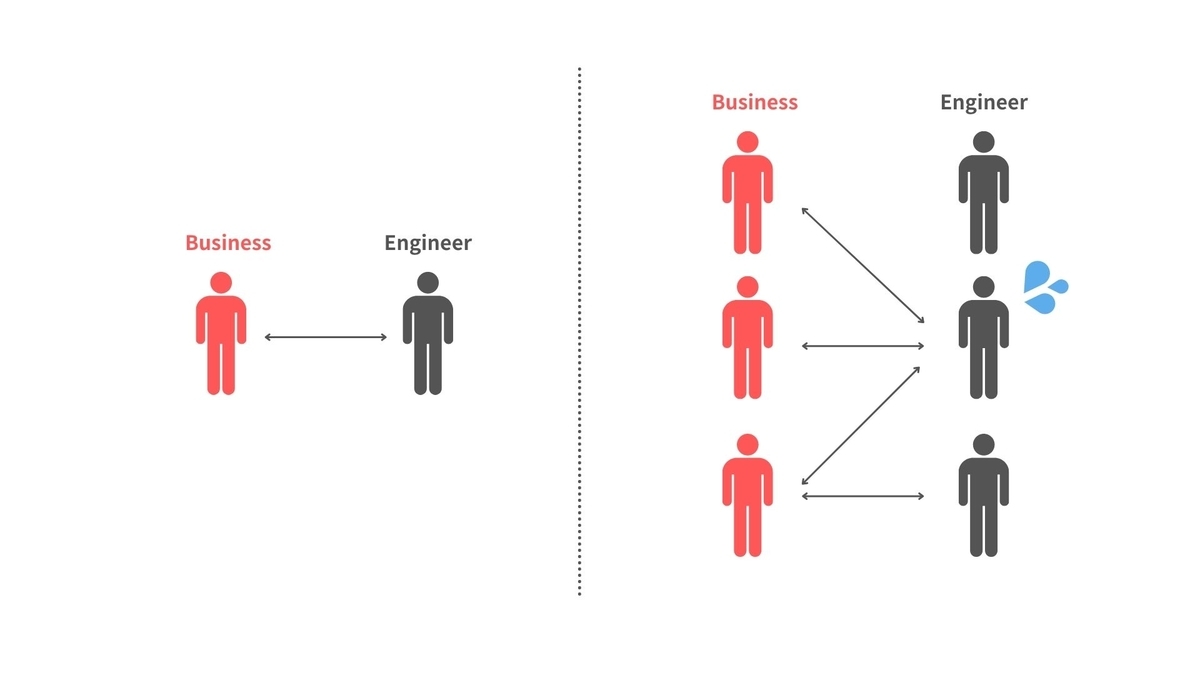
バグ対応におけるコミュニケーションパスには組織規模に応じて適切な数があります。ここでいうコミュニケーションパスとは、ビジネスメンバーとエンジニア間でのバグ対応に関するやりとりの線のことです。エンジニアAさんとビジネスメンバーBさんの2名だけの組織であれば、これは1本だけになり、ここにビジネスメンバーCさんが加わると、A<=>B、A<=>Cと2本になります。
では、この組織が数十名、数百名と増えていくとどうなるでしょうか?コミュニケーションパスはそれに比例して増えていくのでしょうか?
結論はNoです。
もちろん一定数は増えるでしょうが、コミュニケーションパスは無数には増えません。何故ならビジネスメンバー、エンジニアともに「役割」や「経験・ドメイン知識」が固定化されてくるためです。
例えばこんなことはないでしょうか?
カスタマーサポートAさん「お客様から機能Xの問い合わせが来てるな...急ぎで対応しないとな...でも夜遅いし...。あ、Bさん!ちょっとこの前対応いただいた機能Xなんですが...」
エンジニアBさん「ん?ああ、あの件ね。あー、これはあれが悪さしてるぽいな。ちょっとやっておくね」
カスタマーサポートAさん「ありがとうございます!!」
めでたしめでたし。いつも機能Xの対応をしているBさんの迅速な対応のおかげですぐにバグは解消されました。そして同時にこのAさんのBさん間のコミュニケーションパスが確立され、「機能XについてはBさん」という"エンドポイント"が生まれました。Bさんはいつも最低限のパラメーターで迅速な対応をしてくれるエンドポイントなので、Aさんはもちろん他のビジネスメンバーも喜んでこの「Bさんエンドポイント」を叩いてきます。その結果、属人的な対応フローが誕生してしまいます
組織が拡大するとどうしても各メンバーの役割、経験やドメイン知識に偏りが生まれます。その結果、コミュニケーションは、その都度最適な人同士でよしなな方法で行われるようになります。よって、パスは増えないものの、歪なかたちで固定化され、属人化を促進する要員になります。
まず、このコミュニケーションパスを整理することは属人性の排除につながります。具体的な方法については後述します。
2. "パラメーター"を共通化すると、みんなハッピーになる

コミュニケーションパスはエンドポイントと例えましたが、この時発信する側伝えられる情報はリクエストのパラメーターに似ています。
例えば、バグ対応の時に必要な情報は都度異なります。バージョン情報が必要な場合もあれば、アカウントのIDとバグ発生箇所の画面だけでいい場合もあります。このパラメーターの数は、エンジニア側のドメイン知識が深ければ少なく済みます。最低限の情報でバグ特定をすることができるからです。しかし、このパラメーターが最適かどうか?はエンジニアのドメイン知識だけでなく、発生したバグによって変わることもあります。
カスタマーサポートAさん「アプリのバージョン2.4、機能Xでエラーになります。いつものやつだと思います。」
エンジニアBさん「了解です。確認します。」
...確認を進めるBさん、しかし指定のバージョンでバグ再現せず...
エンジニアBさん「バグが発生したアカウントのIDもらえますか?あ、あと発生日時も。」
カスタマーサポートAさん「ユーザーさんに聞いてみます」
熟練のBさんでもバグの原因が異なればいつもの情報だけでは解決できず、追加で情報を確認しないといけません。さらに、これがユーザーに確認しないといけない場合、ビジネスメンバーの工数の負担にもなります。結果としてバグ解決のリードタイムが長くなり、ユーザー体験を毀損することになります。
このパラメーターの種類はバグの種類に関わらず常に一定であるべきです。
バグが発生した日時、ユーザーのID、画面のURL、発生日時、スクショ画面など。ビジネスメンバーからエンジニアへのバグ依頼時のパラメーターは常に一定にしておくことで、バグ対応がスムーズになるだけでなく、今後発生した似たようなバグの対応においてもその時の情報が役に立つことがあります。要はバグ修正の当事者だけでなく、今後のチームメンバーが参照できる貴重な情報源にもなるわけです。
3. バグ対応の進捗は適切にViewに反映する

Aさん、Bさんの迅速な対応によってバグが解決したとします。めでたしめでたし...と思いきや、同じような事象がユーザーから問い合わせが来たカスタマーサポートのCさんがSlackで別のエンジニアDさんに質問します。
カスタマーサポートCさん「Dさん、こんな問い合わせが来たんですけど、ちょっと確認してもらえますか?!」
エンジニアDさん「なんだと?!すぐ確認します!」
...データを確認するDさん。しかし、どうやってもそのバグが再現しない...。
エンジニアDさん「Bさん...ちょっとこんなバグが発生してるらしいのですが、どうやっても再現しなくて...」
エンジニアBさん「え、それならさっき解消したよ?」
エンジニアDさん「?!」
同時多発的に起きたバグが、違うコミュニケーションパスによって報告され、そして余計なリソースを使ってしまったという例です。コミュニケーションパスが増えるとこのようなことが起こりやすくなります。
この場合誰が、どうすればよかったのでしょうか?
簡単な方法として、はじめにバグ対応をしたBさんがSlackなどのコミュニケーションツールで「機能Xのバグを対応しました」とチームに展開することが考えられます。情報共有することで、他のチームメンバーはBさんが問題に対処してくれたことを知ることができます。そのためすれ違いでバグ対応依頼があがってきても、Bさんの情報共有をもとに判断することができます。
しかし、この場合情報共有されていないメンバー(ex. カスタマーサポートのDさん)はこの対応状況を知り得ません。またSlackなどのチャットツールで対応状況を共有しても、情報が流れてしまったり、その対応詳細をメンバーは知ることができなかったりします。どういう事象で、どういう対応をしたのか?などを知らないと正確な対応はできません。
ここでMVCのV(View)の考え方を用います。
Controller、Modelで処理された結果は適切にViewに反映されるべきです。複数のエンドポイントが叩かれるような場合にそれぞれのリクエストの結果が網羅的に理解できるようなViewが適切です。
私が所属するWevoxチームではmondayというタスクツールを使っていて、全員がそのmonday上でタスクの進捗を確認できるようになっています。もちろんバグ対応の進捗、例えば誰がどんな対応をしているのか、またそれがどこまで完了しているのか、を一覧で確認できます。原則として大きなバグでない限りはSlackで報告する代わりに、このmonday上でステータスを更新し、適切なメンバーに伝えるだけで済んでいます。
ここでさらに大事なのは、Controller、Modelでのデータの処理の進捗がわかるViewであることです。
一般的にバグ対応は全関係者が一刻も早く解消することを望んでいます。一方でそのバグがいつ終わるのか、またどれくらい深刻なのか?は対応するエンジニア本人にしかわかりません。もしここがブラックボックス化してしまうと、ビジネスサイドのメンバーとしては不安が募り、ユーザー対応にも影響が出ます。
みなさんも様々なアプリケーションを使うなかで、ボタンを押してLoading状態の時に画面が何も変わらないと不安になりますよね。それと同様に、エンドポイントを叩いたらその結果・進捗がViewに反映されることが望ましいといえます。
4. データの処理(Model)を切り分ける

バグ対応には一定のパターンがあります。例えば、デザインの崩れ、データの不整合、意図せぬ挙動...etc。バグのパターンに応じて、その対応をする人が振り分けられるというケースが多いのではないでしょうか。サーバーサイドに詳しい人、デザインに詳しい人など。
例えばこんなバグ報告があったとします。
「機能Xにおいて画面にデータが正しく表示されない」
この一文には様々な"Model"が存在します。
- 機能Xの修正(さらにその中にデータごとの分類)
- データを表示するフロントの修正
- データを返しているAPI( サーバーサイド)の修正
エンジニアは様々な要因の中から仮設を立て、問題を切り分け、最終的に原因を特定します。これをコードで表現すると以下のようになります。
class BugReportsController < ApplicationController def new request = BugRequest.new(user_id: params[:user_id], occured_at: params[:occured_at], what_happened: params[:what_happened]) request.investigate end end
バグを報告するController(ビジネスサイドのメンバーとのコミュニケーション)においては、報告した先で具体的にどんなことが中で行われているかを知ることはできないケースが多いでしょう。
そして、このBugRequestModelの中では、受け取った値に応じてエンジニアがあれでもないこれでもないと考えています。
class BugRequest < ApplicationRecord validates :user_id, presence: true validates :occured_at, presence: true validates :what_happened, presence: true def investigate investigate_data_in_db if invalid_data? check_component_props_type if component_error? ... end end
実際にこのBugRequestモデルが行なっていることは、発生した事象と受け取ったパラメーターを元に仮説立てをして、様々な点をチェックすることです。しかし、実際にバグ対応をするひとはシステム全てに精通しているわけではないことも多いはずです。データベース、サーバーサイドには詳しいけど、フロントエンドやデザインは知らないという人にコンポーネントの表示バグを依頼することはないでしょう。
つまり、BugRequestモデルの先には複数のさらに細かいモデルがリレーションをもって存在しており、そこでさらに詳細な調査・修正が行われるはずです。これをコードで表すと以下のようなイメージです。(コードが適切かどうかは置いておいて...)
class ServerSide < ApplicationRecord end class FrontEnd < ApplicationRecord end class Design < ApplicationRecord end
class BugRequest < ApplicationRecord has_one :server_side has_one :front_end has_one :design validates :user_id, presence: true validates :occured_at, presence: true validates :what_happened, presence: true def investigate server_side.investigate if server_side_bug? front_end.investigate if server_side_bug? design.investigate if design_bug? ... end end
この例ではアプリケーションをシステムレイヤーごとに切り分けていますが、例えばマイクロサービス化されたものの場合は、これがサービスごとに分かれるはずです。サービスXの調査、サービスYの調査...etcとバグが発生したサービスごとに依頼先が分かれるでしょう。
このようにバグ調査、対応にはいくつかのレイヤーが存在しており、発生した事象に応じて実対応をする"Model"が変わるはずです。
しかし、これを1つのModelで常に処理をしようとすると問題が発生します。
例えば、「バグ対応担当はBさんだから常にあの人に依頼しよう」となると、Bさんはドメイン知識があるので迅速に対応をしてくれるかもしれませんが、実際に中で行なっていることは他モデルで行うべきことだったりするわけです。またBさんはクラスメソッドがたくさん生えていくように、アプリケーションのドメイン知識が身に付くかもしれませんが、他Modelはその処理ができないままになってしまいます。
こうした問題を解消するためにも、バグ対応はModelを切り分けるように依頼先、あるいは実対応を分散させるべきだと考えています。もちろん急ぎの場合だったり、組織がそこまで大きくない場合には"Fat Model"になることは仕方ないでしょう。しかし、プロダクトがスケールするためにも適切なタイミングでModelを切り分けていくことで、ナレッジ共有が進むはずです。
5. Model間の共通処理をまとめる

Modelを適切に切り分けて、みんなハッピー...と思いきや、こんなことは経験ないでしょうか?
サービスX担当のDさん「最近こんなバグがあって、xxxの修正が結構大変だったんですよね〜」
サービスY担当のBさん「あー、それねうちのとこでも結構あるわ。データ変更が多くて怖いよね」
サービスX担当のDさん「そうなんですよ、これ結構時間かかってしまってチームでも議論してるんですけどね...」
サービスごとにバグ対応をしているこの2つのチームでは同じような事象が共通して起こっているようです。そして、それらをそれぞれが処理しています。
しかし、本来的には同じような作業を2つの異なるチームが別々の方法で対処してしまっているという点が問題です。例えば、サービスXではSQLを流してデータ変更を加えている一方で、サービスYではadmin管理画面にバッチ処理を発火する機能を追加しているようなイメージです。
もちろんサービスごとに実際の対処方法は異なるかもしれませんが、共通化できる部分も多いにあるはずです。Model間の共通処理を別Modelに移譲するように、バグ対応チーム、メンバーごとに似たような対応がないか、また再発防止を共通化できないか、などを考えるべきです。Ruby on RailsでいうところのService層や、上位Modelを用意するイメージです。
実際のケースをMVCから考える
さて、ここまで抽象的な話ばかりだったので、最後にWevoxチームではどのようにしているか?をご紹介します。
バグ報告の窓口を一本化、パラメーターを画一化
これまでSlackなどで個別に連絡があった部分を、常にmondayのformから報告していただくようにしています。

私たちが使っているmondayはタスク管理だけでなく、そのタスクの入力をformとして公開することができます。Google Formのように、formに入力された値をもとにタスクが生成され、担当者のエンジニアに通知がいきます。元々Slackで報告、進捗を共有していた時に比べて、monday上で一元管理できるようになったこと、またバグ報告のフォーマットが統一され、報告者・エンジニア間のコミュニケーションコストが下がりました。
ただし、緊急の依頼の場合はSlackで直接連絡が来たり、Slack上で適切な関係者を巻き込んでやりとりした方が早かったりするので、必ずしもこのformに沿わないといけないというわけではありません。この点もチームやプロダクトの特性に応じて適切に"エンドポイント"を切り分けた結果だと思います。
バグ対応の進捗を見える化
monday上でタスクの進捗を見える化しています。具体的には以下のようなステータスを用意しており、関係者が適切なステータスに適宜変更しています。
- 1次調査中: バグ報告を受けた人("一次受け担当")が調査している
- 対応中: 実際の修正作業をしている
- 確認中: バグ報告者に作業完了報告をして、問題解決したかどうか確認中
- 完了: 完全に問題が解決した段階
Controllerの処理結果がViewに適切に反映されるように、なるべく細かく進捗ステップを入力しています。特に、急ぎの対応の場合にはバグ報告者だけでなく、周りの人もいまどんなステータスなのか気になるものです。なるべく誰でも進捗が確認できる状態がチームにとって望ましいと考えています。
またこのようにステータスを明確化することのメリットとして、「いまこれ誰ボールなんだっけ?」という漏れを防ぐことができます。例えば、エンジニアは作業が完了したと思っていたのに、バグ報告者としてはその連絡待ちだったというケースがあります。このようなポテンヒットが起きないように、ステータスを更新し、ボールを適切な人に渡すということが徹底されます。
バグ対応を属人化しない
Wevoxチームはここ1,2年で事業もチームも大幅に拡大、変化してきました。以前はドメイン知識が深い人がバグ対応を行ったり、その時々手が空いている人が対応していたりしました。結果としてナレッジが属人化してしまうことも見られました。
現在ではこのバグ対応をまず2つの大きなModelに分けています。
- 一次受け担当
- 修正担当
一次受け担当とはその名の通りバグ報告者からの連絡をまず受け取るひとです。このひとはその内容を精査し、またログやデータを確認します。そして、その後の実修正は原則行わず、適切な人にアサインしますWevoxではサービスごとにチームが分かれていることもあり、一次調査の結果怪しいと思った箇所のサービス担当に依頼をします。
この一次受けの人は週次で交代制だったり、固定だったりします。交代制の方が全エンジニアが調査スキルが身につくので好ましいと思っています。
よくある修正への対応
バグ対応ほど緊急度が高くなく、かつ修正工数が低い、データ変更などはなるべく誰でもすぐにできるような状態にしています。Railsのrake taskにしていたり、またadmin管理画面にデータ変更の画面を作成し、エンジニア以外でも処理ができるように配慮しています。
さらに、Wevoxチームでは四半期に一回チーム全員でプロダクト改善をする取り組みをしており、溜まった改善点などを一斉に改修したりしています。改善点は一部の人が出すのではなく、全メンバーが誰でも投稿できる状態になっており、これを精査して、Issueとして残しています。
抽象度をあげて、業務を俯瞰してみる
日頃多忙なタスクに追われるなかでも、一度立ち止まっていまチーム・個人がどのような状態か?を俯瞰してみることが大事です。
常に組織は変わり続け、市場の変化によってプロダクトも変わっていきます。だからこそ、定期的にいまどんな状態なのか?を考え、またどうすべきか?を議論することで、常に改善し続けられるチームでいられるのではないでしょうか。またこうした客観視は「なんかヤバい」と思ったタイミングでするより、なるべく早いうちから行うべきだと思います。
本記事ではMVCというアーキテクチャを例にとって考えましたが、組織もある種のシステムです。人という構成要素が組み合わさり、各人のもつ役割や機能によって成り立っています。これを抽象的に捉え、見つめ直すことは、エンジニアの得意分野なはずです。上述の方法に囚われず、みなさんの思う「私たちのチームのアーキテクチャ」について考えたり、議論してみてください!
またこうした議論が好きな方は、アトラエではそういう機会がたくさんあるので、是非一度カジュアルにお話ししてみませんか?