
こんにちは、Docker の申し子 小倉です。
この記事は、株式会社アトラエアドベントカレンダー2020年 24日目の記事です。昨日の記事は@Tech-makoton のキャッシュについて、わかりやすくまとめてみた でした。
今回は Google Cloud Platform のサービスである AI Platform Pipelines をパイプラインツールとして選定した理由と、実際に運用した上での所感について書いていきます。
パイプラインツール利用の背景
弊社では wevox という SaaS を提供しています。システムとしては組織の各従業員に配布したサーベイの回答結果を集計・分析した上でサービス上に描画するということをしています。比較的大規模な回答データ、従業員データ等を扱っており機械学習機能も開発、提供しています。
本番環境で動くモデルもあれば、開発環境でデータサイエンティストが作成するモデルもあり、データサイエンティストとエンジニア(特にインフラ)の業務上のコミュニケーションもかなり増えていました。例えば
- 学習のためのマシンを用意して欲しい
- リソース調整を自動化して欲しい
- 実験管理をしたい
- 前処理、学習、評価までの一連の処理における共通化や抽象化をしたい
などです。
そのためいわゆるパイプラインツールの導入を検討しはじめました。それが2020年3月頃です。 いくつかチーム内で要件を決め、それに沿ってパイプラインツールを列挙、評価しました。結局選ばれたのは AI Platform Pipelines でした。
AI Platform Pipelines とは
Kubeflow Pipelines のマネージドサービスです。まずは AI Platform Pipelines の前に、Kubeflow Pipelines の説明させてください。
Kubeflow Pipelines は、データ取得 → 前処理 → 学習 などの汎用化・共通化できるパイプラインを構築・管理するツールです。Kubeflow 自体は TFX という Google の機械学習プロジェクトを源流とするプロジェクトで、Pipelines 含め Notebooks, Training, Serving 等のための他ツールも備えています。
Kubeflow Pipelines を使うと、機械学習における各種処理を、ワークフローとして Kubernetes 上で実行することが可能になります。
例えば Kubeflow Pipelines を利用すると以下のようなパイプラインを作成することが可能になります。ワークフローの各ステップを Component、ワークフローの全体を Pipeline と呼びます。

Component は独立したコンテナになっており、Kubernetes の恩恵によってそれぞれのコンテナに対して CPU/GPU やメモリの割り当てができます。また実験管理も可能でデータの基礎統計量、TFDV、テーブルデータのスキーマはプリセットツールで見ることが出来ます。加えてデータリネージが可能です。
Kubernetes に関わるリソースは YAML で書くことがほとんどですが、 Kubeflow Pipelines は Python SDK である kfp を習得すれば Kubernetes 上にパイプラインを構築できます。そしてここまでの処理を、Jupyter Notebooks 上で実行できます。
ここまでが簡単な Kubeflow Pipelines の説明です。
AI Platform Pipelines ではマネージドサービスとして Kubeflow Pipelines を利用することが出来ます。
マネージドとして利用することで、GUI 複数クリックで Kubeflow Pipelines が利用可能な状態になります。インストール先は既存の GKE(Google Kubernetes Engine) クラスタでもいいですし、新規の GKE クラスタを作成しつつインストールすることでも可能です。
また Kubeflow のレイヤーではなく GCP のレイヤーとして扱えることで他の GCP リソース、特に AI Platform のサービスとの連携が容易になります。後述しますが他の GCP リソースと容易に連携できることがこの AI Platform Pipelines を利用する大きなメリットの1つだと思っています。
選定の背景
第一に、GCP でマネージドサービスとして利用できることです。 wevox チームではもともとサービスのホスト環境として AWS を、データ分析環境として GCP を利用していました。 特に BigQuery は計算資源としてかなり優秀であるため、他機能提供に利用していたりビジネスサイド含めチーム内のメンバーが多く利用していたりしていて既に実績がある状態でした。そのためデータサイエンティストがメインで作業するクラウドとしては AWS よりは GCP であれば嬉しいかなとは思っていました。
また、Kubeflow Pipelines では各 Component(というかコンテナ)から簡単に GCP サービスでのジョブ実行が出来ます。 例えば以下の画像では、extract_data という名前の Component が実行されると GCS や BigQuery を使ってデータの取得を行ってきます。また train_model では AI Platform Training を使って学習ジョブを行う、というように GCP の各種リソースを使いながら機械学習の諸作業を楽することができます。

第二に、AI Platform Pipelines がβ版としてリリースされたことです。 私が技術選定を始めた頃にちょうどバージョン1.0がリリースされました。またそれに伴い、AI Platform Pipelines も直後にβリリースされました。
第三に、Kubernetes クラスタの社内運用実績があったことです。 GKE もマネージドではありますが、クラスタを設計・構築したり、トラブルシュートしたりするとやはりそれなりの知見が必要になってきます。幸い、プロダクト自体は AWS EKS(Elastic Kubernetes Service)で運用していたり、他にも数名の運用経験者がいたりと社内で知見を共有できる土台はありました。
また wevox では既に Argo という Kubernetes ネイティブのワークフローエンジンを本番環境で利用していました。実は Kubeflow Pipelines は Argo を利用してパイプラインを作成しています。そのため Kubeflow Pipelines の考え方や使い方は Argo に似た部分があります。
Kubernetes や Argo の運用経験があったことも、すんなりと Kubeflow Pipelines を利用できたことの理由かもしれません。
ちなみに当時候補に挙がったサービスを振り返ってみると相当数のパイプラインツールがあったと思います。
運用の所感
AI Platform Pipelines を運用した上で感じたことをいくつか書いていきます。
AI Platform の思想を理解したほうがいい
AI Platform Pipelines はそれ単体で使うというよりも、AI Platform の他サービスの組み合わせで利用したほうがいいと思います。そのためそれに先立ってどのような思想で各サービスが作られているかを考えたほうが良さそうです。
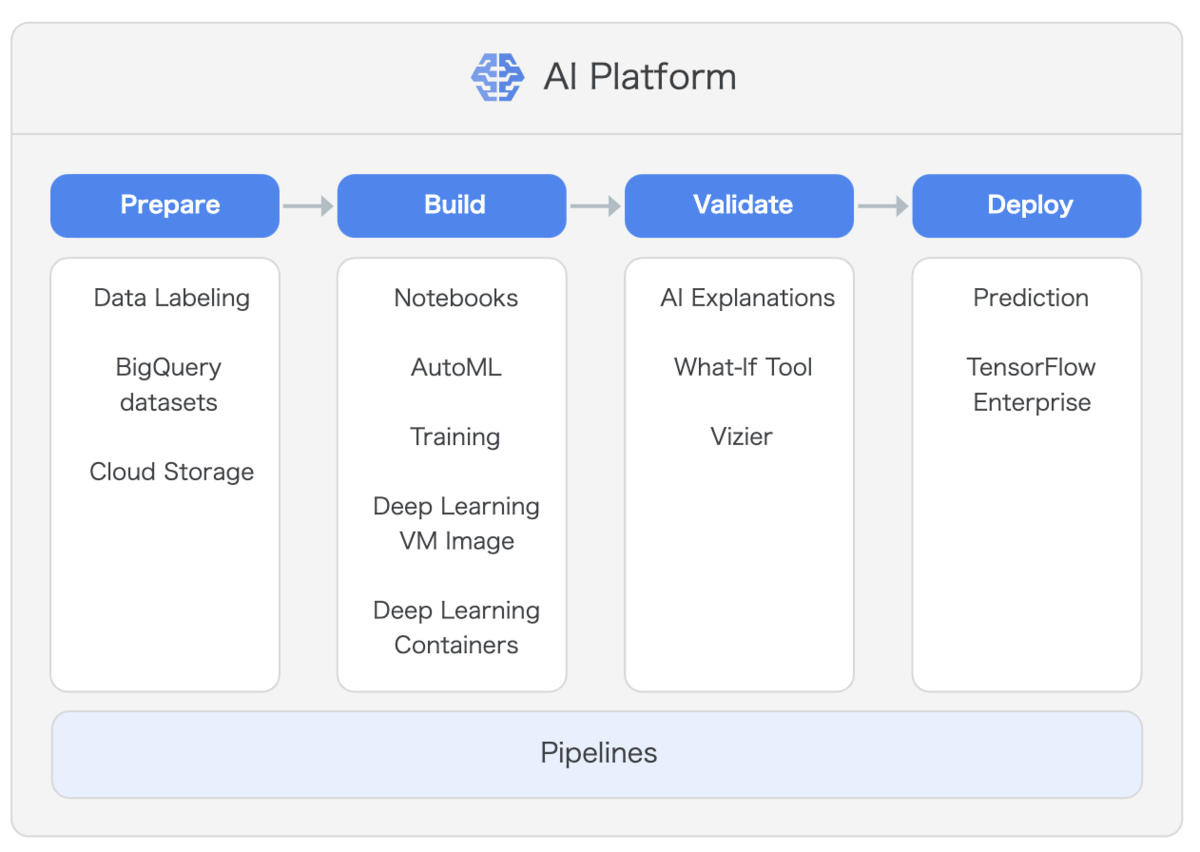
上の図は GCP からの出典ですが、Pipelines が機械学習の各ステップを支える形になっています。AI Platform Pipelines では Component 内から BigQuery や AI Platform Training を行うことになると上述しました。基本的には、AI Platform Training や AI Platform Prediction、BigQuery 等の各種 GCP リソースに機械学習の各作業を任せ、その順番をワークフロー、パイプラインとして管理、実行させるために AI Platform Pipelines をメタ的に利用するものだと解釈しています。また各 Component 間のデータの受け渡しは GCS が推奨されています。
この設計思想を先に理解しないと、実装で辛くなったり、どのような設計にするか途方にくれたりしてしまいそうです。例えば AWS では Sagemaker の提供してくれている作法に乗っかることで楽に機械学習機能の提供ができるように、GCP でも AI Platform の提供してくれている作法に乗っかるのが良さそうです。
構築、運用はある程度データサイエンスの知識があるとよい
自分たちの場合は GKE 構築及び AI Platform Pipeline の試験的な利用はインフラエンジニアが、ガリガリとコードを書いて実際に運用するための感覚を掴むのをデータサイエンティストがやるというように役割分担していました。一方で Kubeflow 自体は、エンジニアとデータサイエンスとの垣根を無くすことを目指しているため、上述のように Kubeflow の思想を理解するにはデータサイエンスの生態やつらみを知っていることで、その理解がしやすくなるような気がしています。
望ましくは構築した本人が Python でガリガリとコードを書いて、コンテナにして、それを AI Platform Pipeline で動かすというのがスピーディかつ情報伝達としては効率が良さそうです。
Kubeflow Pipelines に必要な細かなモジュールの指定が不可
これはマネージドであるため仕方ないことではあります。 4月くらいにインストールした Kubeflow Pipelines インスタンスのバージョンと、8月くらいにインストールしたインスタンスのバージョンが違うことでいくつかサービスが動かなくなるというトラブルが起きました。開発環境だったので良かったことではありますが…
バージョンを明示的に上げたわけではなく、別クラスタに新しくインスタンスをインストールしたら、そのインスタンスのバージョンが上がった状態で固定されていました。そのため古いバージョンに戻すと行ったことが出来ませんでした。
AI Platform 側でいくつかのバージョン内から選択できるわけではないため、別クラスタにインストールする時はそのあたりを認識しておく必要がありそうです。
総合的な所感
AI Platform を使いこなしているわけではありませんが、やはり便利です。 マネージドであるため、本来やりたいところに注力できたり、GKE を使ってリソースの自動調整ができるようになります。
マネージドであるがゆえの制限もなくはないですが、思想を理解した上で付き合っていけばかなり大きい規模の企業やサービスにも対応できるようなサービスだと考えています。
最後に
Kubeflow Pipelines に関する記事をいくつか書きました。
Kubeflow Pipelines の Python SDK についてです。
GKE 上に AI Platform Pipelines インスタンスをデプロイする方法についてです。
Kubeflow Pipelines 含め、wevox で利用しているデータ分析環境についてです。